Maximum Flow
The problem:
Imagine that you work in central London. Every morning you take the tube to get to work. Once the train arrives, a lot of people try to get from the platform to the exit. The problem is, everyone walks very slowly cause it's so busy. There are multiple possible paths from the platform to the exit, each consisting of a number of corridors and there are points where these paths intersect forming crossroads. Each corridor can only be walked in one direction and has a limited capacity so that only up to a number of people can walk in it at the same time.Because you're smart and like algorithms, TFL decided to give you the task of calculating the optimal way in which people can be sent along the various paths, so that the maximum number of people can get from the platform to the exit at the same time.
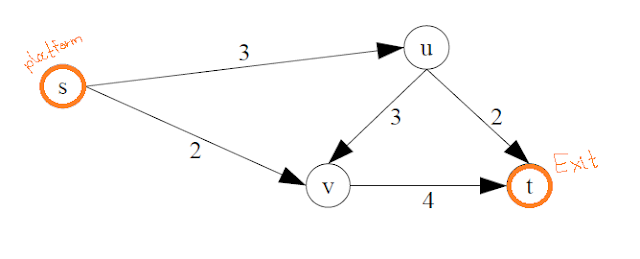 |
| A simple network flow graph |
A network flow graph G = (V, E) is a directed graph with two special vertices: the source vertex s, and the sink (destination) vertex t. Each other vertex represents a crossroad. An edge (u,v) in the graph means that there is a corridor from u to v. Each edge has an associated capacity which is finite, representing the amount of people that can use the corridor.
A first attempt:
So, how can you approach this problem? A straightforward solution is to do the following:- keep finding paths from the platform to the exit where you can send people along
- send as many people as possible along each path
- update the flow graph afterwards to account for the used space.
Let's randomly choose the path s -> u -> v -> t. The capacities along this path are 3, 3, 4 respectively. But we can only send as many people as the smallest corridor can take, which is 3. This is the bottleneck capacity.
Now we send 3 people along this path and try to update the graph to reflect that we've used up 3 out of the total capacity. A way to do that is to decrease the capacity of each corridor we used by 3.
 |
| Every edge is annotated with how much flow we sent out of the total capacity |
Now the only other path left is s->v->t. The edge (s,v) has capacity 2, and the edge (v,t) now has capacity 1, because we have already sent 3 people along this corridor.
With the same update procedure we obtain this graph:
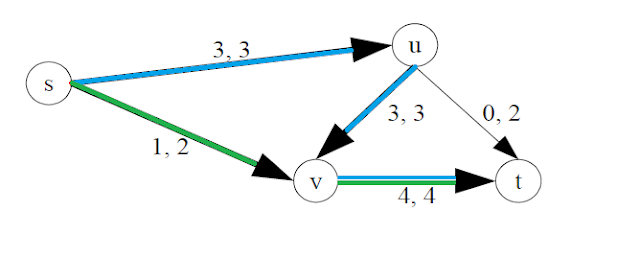 |
| Algorithm ends, but this is not optimal |
Now our algorithm ends because there aren't any other paths from s to t with free space.
Is our solution the optimal?
It turns out we could have done better. If we had only sent 2 people on (u,v) and diverted the third person to (u,t), then we would have opened up a new space in both edges (u,v) and (v,t). We could then send one more person on the path s->v->t, increasing our total flow to 5.
The optimal solution is the following:
 |
| The optimal solution |
What went wrong with our algorithm? Let's take some time to observe what is exactly the difference between the suboptimal and the optimal solution.

One way to interpret the difference is this:
We try to send one more person along s->v. He gets to v easily as there is available capacity. But then at the v crossroad, we have 2 people coming from s, and 3 people coming from u. As (v,t) has only a capacity of 4, they can't all continue forward.
So, we
A better attempt:
It turns out that this fix yields a correct solution to the maximum flow problem.I'll summarize the algorithm:
- Initially, the flow on every edge is 0. We associate a capacity function along each edge c(u,v), that tells us how many units of flow can go from u to v. Initially, c(u,v) is set to the maximum capacity for each edge (u,v) and the flow f(u,v) on every edge is 0.
- Keep finding paths from s to t using two types of edges: (these are called augmenting paths)
- Forward edge (u,v) if f(u,v) < c(u,v).
That's the normal case where we can send a person along an edge as long as it's not filled to capacity. - Backward edge (v,u) if f(u,v) > 0.
That's the case where a person that originally went from u to v (thus f(u,v)>0), has to be sent back to u. - Send flow along the path equal to the bottleneck capacity. The bottleneck capacity is the minimum capacity of all edges in the path. That is
- for forward edges: c(u,v) - f(u,v)
- for backward edges: f(v,u)
- Update the graph:
- increase flow on forward edges
- decrease flow on backward edges
Example implementation:
We use a BFS to find an augmenting path in each step from s to t. In prev[] we store the parent of each node, and -1 means it's unvisited. Once we find a path to t, we trace it back to s using prev[] in order to calculate the bottleneck.
This algorithm is called the Ford-Fulkerson Algorithm after its inventors.
Time complexity
The running time of Ford-Fulkerson is O((n+m) * F), where m is the number of edges, n the number of nodes, and F is the maximum flow in the graph. This is because we can do at most F augmenting paths. Each one being a BFS needs O(n+m) time. (In the snippet above though the BFS takes O(n^2) because it uses an adjacency matrix).
However Edmonds and Karp proved that if we always find the shortest augmenting path first, then we can achieve a better bound. Since BFS already finds the shortest path in an unweighted graph, the implementation above is already the Edmonds-Karp algorithm. This runs in O(m^2 * n) time with an adjaceny list and O(m*n^3) with an adjacency matrix. There are better and more complicated algorithms that solve the maximum flow problem in O(m*n^2) and even O(n^3) that can be found in CLRS.
Maximum Bipartite Matching
The problem:
Let's consider another problem. You finally get out of the tube and go to your office ready for some coding. But today everyone must pair program! There are two development teams, A and B, and in order to increase collaboration between the teams, today people from team A must pair with people from team B. The problem though is that every developer from team A, only likes to pair with a subset of developers from team B, and vice versa.
Your boss knowing you like graph algorithms, gives you a list of people that each developer likes to pair with, and asks you to find what is the maximum number of developer pairs between team A and B, so that in each pair both developers like to pair program with each other.
Some terminology:
A bipartite graph is a graph G=(V,E) in which it is possible to split the set of vertices into two non-empty sets, L and R, such that all of the edges in E have one endpoint in L and the other in R.A matching in any graph is any subset, S, of the edges chosen in such a way that no two edges in S share an endpoint.
A maximum matching is a matching of maximum size.
The (same) solution:
In general, the problem of finding a maximum matching in a graph is NP-hard, but if the graph is bipartite there is a polynomial solution.The problem above can be modelled with a bipartite graph. On the left side we have developers from team A, on the right side we have developers from team B, and there is an edge between two of them if they both like to pair program with each other. The answer we are looking for is the maximum matching.

This problem reduces to Maximum Flow. Draw the bipartite graph with team A developers on the left, and team B developers on the right. Give each edge a capacity of 1. Add a vertex s on the far left and connect it to every developer of team A by an edge of capacity 1. Add a vertex t on the far right and connect it to every developer of team B by an edge of capacity 1. Finally, find the maximum flow from s to t.

Example implementation
We could have just used the same code as in the maximum flow problem, but this is a simpler problem because every capacity is 1, so we can simplify the code a lot. Most of the work is done by the bpm(u) function that tries to match the left vertex u to something on the right side. It tries all the right vertices v and assigns u to v if v is unassigned, or if v's match on the left side can be reassigned to some other vertex on the other side. This is just another way of implementing DFS.
This concludes this post on Maximum Flow, I hope you enjoyed it.